




































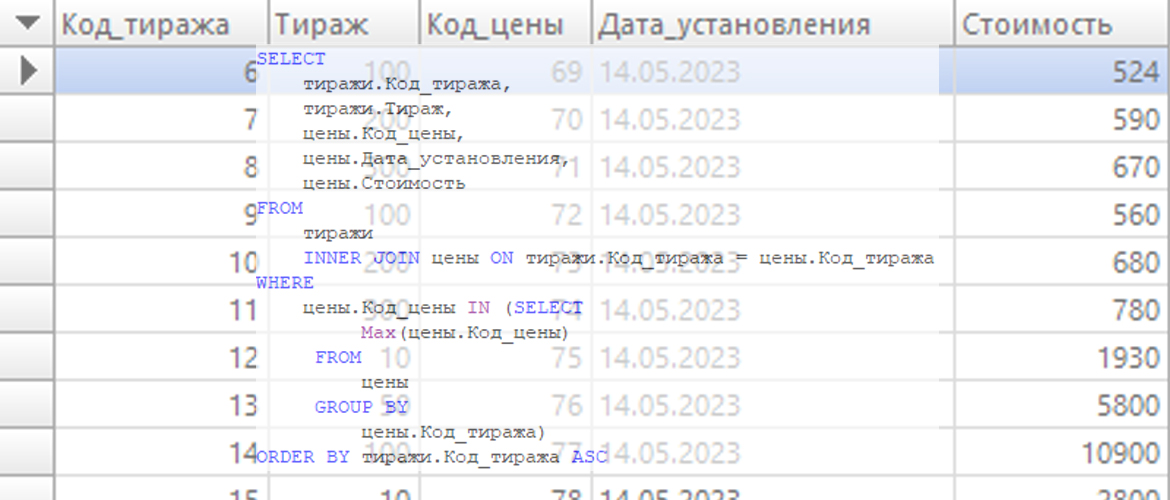
Добрый день, давайте посмотрим на один из видов запросов, который на практике осуществляется довольно часто. Идея состоит в том, чтобы сгруппировать таблицу таким образом, чтобы в строке получить максимальное значение по группируемому полю. Я часто видел, как многие задавались вопросом о том, как это сделать. Я также видел множество решений этого вопроса, которые мне показались довольно сложными и громоздкими. Объясню, как я делаю такую выборку. Она может быть очень полезна тем, кто регулярно сталкивается с этой проблемой.
Все дело в том, что когда вы делаете группировку в запросе, то в результат обычно попадает значение, первой записи из группы. Но это далеко не всегда является тем, что мы бы хотели видеть в качестве результирующих данных. Давайте посмотрим на простой пример.
Допустим у нас типография, в которой есть тиражи и цены. Мы не будем брать всю базу данных с названием печатных продукций, услуг и прочее, а возьмем только две таблицы. Одна из таблиц будет называться «Тиражи», а другая «Цены».
Вполне себе очевидно, что одному и тому же тиражу будет соответствовать множество цен. Это происходит потому что, со временем цена на тираж может измениться. Естественно, что старая цена должна остаться в базе данных, потому что она уже участвовала в оформлении сделок по оказанию услуг типографией. И если цена изменилась, то следует добавить новую. При этом две таблицы будут иметь вид связи один-ко-многим.
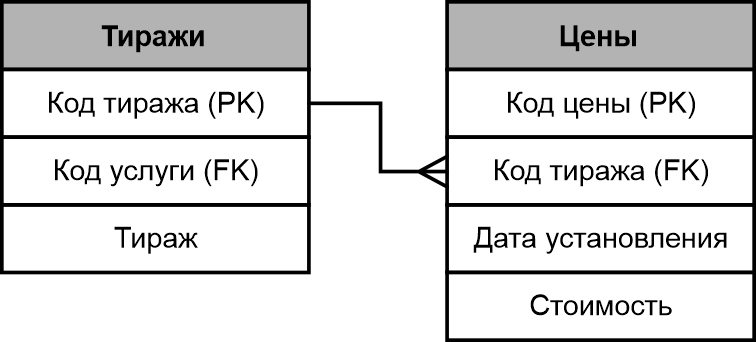
Две таблицы данного примера связаны по через ключевое поле «Код тиража». Таблица «Тиражи» является главной, а таблица «Цены» — подчиненной.
Если сейчас выполнить выборку, на основании двух таблиц следующим образом:
SELECT
тиражи.Код_тиража,
тиражи.Тираж,
цены.Код_цены,
цены.Дата_установления,
цены.Стоимость
FROM
тиражи
INNER JOIN цены ON тиражи.Код_тиража = цены.Код_тиража
то мы получим результат дублирования записей, который мы можем видеть ниже:
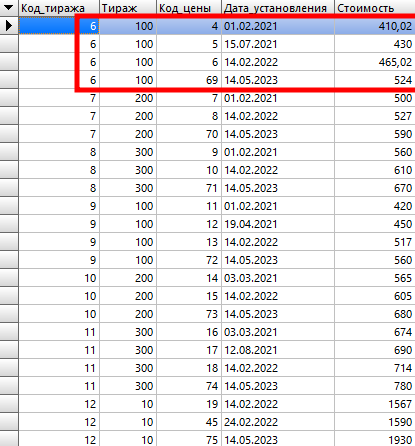
Здесь видно, что по шестому коду тиража в количестве ста единиц было несколько цен, которые устанавливались в разные периоды времени. Но нам нужно узнать актуальную цену (стоимость). Для этого проведем группировку по полю «Код тиража».
SELECT
тиражи.Код_тиража,
тиражи.Тираж,
цены.Код_цены,
цены.Дата_установления,
цены.Стоимость
FROM
тиражи
INNER JOIN цены ON тиражи.Код_тиража = цены.Код_тиража
GROUP BY тиражи.Код_тиража
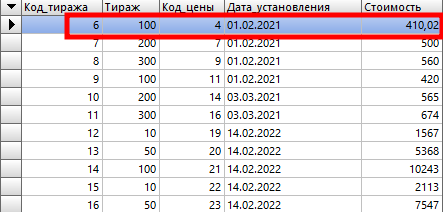
Что же мы теперь видим? Мы видим прекрасно сгруппированный результат запроса, но одним большим «Но». Стоимость показана на верно. В группу попадает первая запись со стоимостью (код цены «4»). А нам нужно, чтобы это была последняя цена.
Для решения этой проблемы удобно использовать подзапрос и выполнить основной запрос на основании подзапроса. В подзапросе нужно получить максимальное значение по группе нужного столбца. Для этого нам в подзапросе нужно получить всего один столбец. Этот столбец будет использоваться для основного запроса как список значений в условии WHERE IN. И этим столбцом будет являться результат агрегированной функции Max, то есть максимальное значение по полю. В нашем случае я выбрал поле не стоимость, а поле «Код цены». Почему? Потому что в течении времени стоимость на определенный вид услуг может не всегда увеличиваться. Иногда более поздняя стоимость может быть меньше, чем, например, стоимость в начале года. И тогда в выборку попадет не последняя цена, а та, которая была больше за всю историю. Используя же код цены в качестве такового поля можно быть уверенным в том, что наивысший код цены как раз всегда будет актуальным, так как это поле является первичным ключом в таблице «Цены».
SELECT
тиражи.Код_тиража,
тиражи.Тираж,
цены.Код_цены,
цены.Дата_установления,
цены.Стоимость
FROM
тиражи
INNER JOIN цены ON тиражи.Код_тиража = цены.Код_тиража
WHERE цены.Код_цены IN (SELECT Max(цены.Код_цены)
FROM цены
GROUP BY цены.Код_тиража)
ORDER BY тиражи.Код_тиража ASC
В результате этого запроса мы увидим правильный результат:
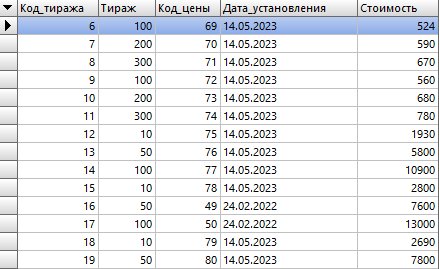
Здесь каждому коду тиража соответствует последняя актуальная стоимость.





