





































SQL запросы к базе данных к базе данных являются основным источником получения информации из базы, а также средством модификации данных.
Что такое SQL-запросы к базе данных
SQL-запросы к базе данных представляют из себя несколько команд языка SQL.
Виды запросов к базе данных
Все запросы к базе данных можно условно разделить на четыре основные группы:
- INSERT INTO — команда-запрос, позволяющая осуществить добавление записи в базу данных;
- DELETE — команда-запрос, позволяющая осуществить удаление одной или нескольких записей из базы данных;
- UPDATE — команда-запрос, позволяющая провести модификацию записей в базе данных;
- SELECT — собственно запрос на выборку необходимой информации в базе данных
Команда INSERT INTO
INSERT INTO Имя_таблицы (Поле_1, Поле_2, ... Поле_N) VALUE (Значение_1, Значение_2, Значение_N)
Пример:
INSERT INTO Пользователи (ФИО, Дата_рождения, Роль) VALUE ("Иванов И.И.", "1982-07-25", "Администратор")
Здесь мы в таблицу «Пользователи» добавляем в поля «ФИО», «Дата рождения» и «Роль» значения: «Иванов И.И.», «1982-07-25» и «Администратор» соответственно.
Команда DELETE
Команда удаляет запись или записи из таблицы базы данных.
DELETE FROM "Имя_таблицы" WHERE Условие
Команда удаляет данные из указанной таблицы, при соблюдении условия. Пример:
DELETE FROM Пользователи WHERE Роль="Оператор"
Здесь мы удаляем записи с ролью оператор из таблицы «Пользователи».
Команда UPDATE
Данная команда обновляет записи в таблице базы данных. Синтаксис команды:
UPDATE Имя_таблицы SET Поле_1 = Значение_1, Поле_2 = Значение_2, ... Поле_N = Значение_N WHERE Условие
Пример:
UPDATE Пользователи SET ФИО = "Иванков Алексей Иванович" WHERE Условие ФИО = "Иванков А.И."
В этом примере мы у всех записей, у которых поле «ФИО» равно «Иванков А.И.» поменяли значение на «Иванков Алексей Иванович».
Чтобы, например, очистить поле таблицы от значений можно написать так:
UPDATE Статистика SET Средняя_относительная_ошибка=Null
Или так:
UPDATE Статистика SET Средняя_относительная_ошибка=Null WHERE Код_показателя>0
Здесь мы уже очистили данные только у тех записей, у которых код показателя больше нуля.
Команда SELECT
Команда SELECT представляет из себя запрос на извлечение нужной информации из базы данных. Как известно, вся информация в базе данных хранится в структурированных нормализованных таблицах, объединенных между собой различными типами связей (см. статью «Виды связей между таблицами».
В связи с этим, если запрос извлекает данные из одной таблицы, то необходимо применить однотабличный запрос. Если же необходимо извлечь данные из нескольких таблиц базы данных, то необходимо применить многотабличный запрос.
Вообще синтаксист команды SELECT очень большой и состоит из множества операторов, но на практике применяются только некоторые основные. Вряд ли я смогу в статье рассмотреть все возможности этой команды, но я постараюсь показать самые интересные примеры.
Запросы бывают разные. Бывают простые запросы, бывают многотабличные.
Самый простой запрос, который может быть в природе выглядит так:
SELECT * FROM Пользователи
Звездочка, как все знают, означает, что мы выбираем все поля из таблицы «Пользователи».
Ну а если нам нужно получить, например только ФИО, дату рождения и логин пользователя, то запрос может выглядеть так:
SELECT ФИО, Дата_рождения, Логин FROM Пользователи
Я еще посоветовал бы всегда включать в запрос поле первичного ключа таблицы. Оно часто требуется, например в модели доступа к данным ADO. Тогда запрос может выглядеть так:
SELECT Код_пользователя, ФИО, Дата_рождения, Логин FROM Пользователи
Код_пользователя у нас будет первичным ключом.
Если нам нужны пользователи с фамилией «Иванов», то мы добавляем в конструкцию оператор WHERE и прописываем в нем условие (это все тоже довольно примитивно):
SELECT Код_пользователя, ФИО, Дата_рождения, Логин FROM Пользователи WHERE ФИО='Иванов'
Давайте еще немного усложним наш запрос. Есть разные фамилии, похожие на «Иванов». Есть «Иванков», «Иванников», «Иваненко» и может быть другие. Не суть. Допустим нам нужен пользователь, но мы не знаем его точной фамилии. Тогда мы добавляем оператор частичного соответствия LIKE со знаком %:
Код_пользователя, ФИО, Дата_рождения, Логин FROM Пользователи WHERE ФИО LIKE 'Иван%'
Причем, если поставить % после слова, то выйдут все пользователи с фамилией Иванов, Иваненко, Иванников и другие, которые начинаются с «Иван». Совершенно очевидно, что если вы не знаете фамилии вообще, но знаете отчество, то можно записать вот так:
WHERE ФИО LIKE '%Петр Сергеевич'
Ну а если вам известно только имя, то так:
WHERE ФИО LIKE '%Петр%'
Допустим у нас несколько пользователей с ФИО Иванов Петр Сергеевич. Тогда, например, если мы знаем дату рождения пользователя, мы можем еще более усложним запрос:
SELECT Код_пользователя, ФИО, Дата_рождения, Логин FROM Пользователи WHERE ФИО LIKE 'Иван%' AND Дата_рождения BETWEEN '1982-01-01' AND '1982-12-31'
Обратите внимание, что здесь используется два раза AND. Этот оператор означает «И», то есть, мы выбираем всех пользователей с фамилией, начинающейся с «Иван» и при этом дата рождения должна быть в диапазоне между значениями '1982-01-01' и '1982-12-31' . Оператор BETWEEN означает между. Ну как я уже написал здесь два оператора AND. Поэтому, чтобы не запутать сервер SQL, да и вам тоже, советую заключать их в скобки:
WHERE (ФИО LIKE '%Иванов%') AND (Дата_рождения BETWEEN '1982-01-01' AND '1982-12-31')
Здесь уже более наглядно видно, что есть два условия.
Теперь давайте отсортируем полученный результат по полю даты рождения. Для этого добавим оператор ORDER BY
SELECT Код_пользователя, ФИО, Дата_рождения, Логин FROM Пользователи WHERE (ФИО LIKE '%Иванов%') AND (Дата_рождения BETWEEN '1982-01-01' AND '1982-12-31') ORDER BY Дата_рождения ASC
Здесь мы полученный результат отсортировали. То есть, если у нас вышло 10 пользователей в результате запроса, то мы их расположили в порядке возрастания их даты рождения. За это отвечает оператор ASC. Если же нам нужно в результате получить список с убывающими датами рождения, то вместо ASC следует написать DESC.
Давайте теперь представим такую ситуацию, что мы получили список пусть не из десяти, а из двадцати пользователей, и у многих из них даты рождения совпадают. Тогда их можно отсортировать еще и так:
SELECT Код_пользователя, ФИО, Дата_рождения, Логин FROM Пользователи WHERE (ФИО LIKE '%Иванов%') AND (Дата_рождения BETWEEN '1982-01-01' AND '1982-12-31') ORDER BY Дата_рождения ASC, Код_пользователя ASC
То есть, здесь мы провели сортировку по возрастанию по дате рождения, а внутри этой сортировки мы еще отсортировали по коду пользователя. Есть еще много операторов, но мы их рассмотрим далее в более сложных запросах, потому что это были простые запросы. Они так называются, потому что выборка осуществляется из одной таблицы. Но существуют также многотабличные запросы, когда нам необходимо извлечь данные из двух и более связанных таблиц.
Операторы объединения таблиц в запросе SELECT
Вообще пользователей всегда удобно делить на группы. В связи с чем у нас имеются две таблицы «Группы пользователей» и «Пользователи», объединенные между собой связью один-ко-многим.
Соответственно, таблица «Группы пользователей» является главной, а «Пользователи» — подчиненной. То есть, в каждой группе принадлежат разные пользователи. Технически это выглядит так:
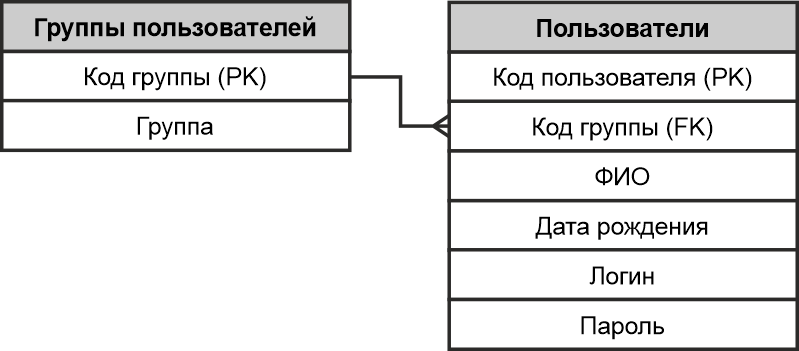
И теперь представим, что у нас существуют четыре группы пользователей:
- администраторы;
- логисты;
- кассиры;
- специалисты.
Давайте посмотрим на то, как могут выглядеть эти таблицы уже с данными:
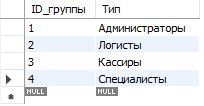

В таблице пользователей есть подин пользователь, принадлежащий группе администраторов (ID Группы = 1), два пользователя, принадлежащие группе логистов (Иванов и Муравлева, у которых ID группы = 2) и два пользователя, принадлежащих группе кассиров (Пыткин и Корниенко, у которых ID группы = 3).
Но вот пользователей, принадлежащих к группе специалистов в таблице нет. И вот давайте теперь посмотрим, как могут выглядеть на этом примере некоторые многотабличные запросы.
SELECT
группы_пользователей.ID_группы,
группы_пользователей.Группа,
пользователи.ID_пользователя,
пользователи.ФИО,
пользователи.Дата_рождения,
пользователи.Логин,
пользователи.Пароль
FROM
группы_пользователей INNER JOIN пользователи
ON пользователи.ID_группы = группы_пользователей.ID_группы
Здесь мы выбираем поля из двух таблиц. Затем в предложении FROM мы указываем, из каких таблиц мы будем извлекать данные, а именно из таблицы «Группы_пользователей» и «Пользователи». А объединяются эти таблице оператором INNER JOIN посредством первичного ключа родительской таблицы и внешнего ключа дочерней таблицы.
Результат такой выборки показан на следующем рисунке:

Обратите внимание, что в результатах выборки отсутствует группа «Специалисты», хотя в таблице «Группы пользователей» эта группа присутствует. Это произошло благодаря оператору INNER JOIN. Данный оператор позволяет извлечь данные из обеих таблиц, для которых в одной и в другой таблице есть совпадающие данные по ключевым полям.
Есть такое понятие, как левая и правая таблица в запросе. Так вот левой таблицей называется та таблица, которая стоит слева от оператора INNER JOIN, а правой — соответственно та, которая стоит справа. У нас слева стоит таблица «Группы пользователей», а справа «Пользователи». И оператор INNER JOIN как бы дает результат объединения .
Очень часто нужно получить сведения обо всех группах (в данном примере). Это можно сделать, если вместо INNER JOIN мы поставим LEFT JOIN. Этот оператор называется левым объединением. Выглядит это так:
...
группы_пользователей LEFT JOIN пользователи
...
Результат такой выборки будет следующим:

Теперь мы видим, что у нас в столбце «Группа» появилась группа «Специалисты». Соответственно далее, по строке данных не будет, ведь у нас нет ни одного пользователя с такой группой.
Бывают ситуации, когда нужно показать все записи из правой таблицы, а из левой показать только те, которые есть в правой. Это делается оператором RIGHT JOIN, который называется правым объединением.
Более того, чтобы получить результат, который у нас показан на предыдущем рисунке можно записать и так:
...
пользователи RIGHT JOIN группы_пользователей
...
Как раз здесь мы выбираем все записи из правой таблицы и записи из левой, которые удовлетворяют наличию значений ключевого поля в правой.
Есть еще оператор FULL JOIN, то есть полное объединение, когда в результирующий запрос попадают все записи из левой и все записи из правой таблицы. ок. Есть еще и другие условия объединения, но они настолько редки, что я за 20 лет ни разу еще их не применял.
Агрегатные функции в запросе SELECT
Долго думал, как дать определение агрегатной функции. Ну наверное будет наиболее верно сказать, то это функции, которые проводят какую-либо аналитику с результатами выборок.
В каждой СУБД существуют свои специфические агрегатные функции, но есть и основные, которые имеются во всех СУБД. Я как всегда все рассматриваю на примере MySQL 8.0.28.
Итак, существуют следующие агрегатные функции:
- AVG — с помощью нее можно получить среднее значение по столбцу;
- SUM — сумма значений столбца;
- MIN - минимальное значение столбца;
- MAX — максимальное значение столбца;
- COUNT — количество записей, которое присутствует после выполнения запроса.
Но мы не можем использовать агрегатную функцию саму по себе. Для ее использования мы должны провести группировку записей оператором GROUP BY.
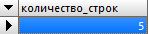
Например, узнаем сколько пользователей в нашей таблице «Пользователи»
SELECT COUNT() as количество_строк FROM пользователи
В результате такого короткого запроса мы получим пять строк:
Давайте немного усложним задачу и возьмем наш запрос на объединение (INNER JOIN), который мы писали ранее:
SELECT
COUNT() as количество_строк
FROM
группы_пользователей INNER JOIN пользователи
ON пользователи.ID_группы = группы_пользователей.ID_группы
Ну единственное, что мы из этого запроса убрали список полей, потому что мы получим всего одну строку и список полей нам здесь не понадобиться. Смотрим, что получилось:
Мы получили тоже самое, то есть эта функция работает и с многотабличным запросом. Давайте еще усложним. Насколько я помню, то выше в этой статье, когда мы рассматривали условия объединения, то мы получили результирующий запрос, в котором у нас был один пользователь из группы администраторов, два пользователя из группы логистов и два пользователя из группы кассиров (при условии объединения INNER JOIN).
Ну так вот, у нас пять записей, в чем мы только что чуть выше убедились. Но давайте теперь посчитаем количество записей не всего, а количество записей в каждой группе, то есть, сколько у нас пользователей в группе администраторов, сколько в группе логистов и сколько в группе кассиров. Для этого нам нужно применить группировку данных совместно с агрегатной функций COUNT. Группировка данных в запросе SELECT осуществляется оператором GROUP BY и выглядеть это будет следующим образом:
SELECT
группы_пользователей.ID_группы,
группы_пользователей.Тип AS Группа,
COUNT() as количество_строк
FROM
группы_пользователей INNER JOIN пользователи
ON пользователи.ID_группы = группы_пользователей.ID_группы
GROUP BY группы_пользователей.ID_группы
Вот что получилось:
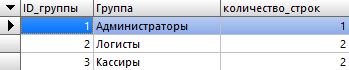
При этом из самого запроса я убрал поля: ФИО, дата рождения, логин и пароль, потому что при группировке две строки объединятся в одну, ну и естественно, что в записи будет показаны данные той строки, которая была первой. То есть, у нас в группе логистов были Иванов и Муравлева, но после группировки в ФИО, дате рождения, логине и пароле будут стоять данные Иванова. Поэтому при группировке следует оставить поля, по которым мы группировали.
Кстати говоря, мы группировали по ID группы, но можно было и сгруппировать по полю Группа. Мы бы получили тот же самый результат, но безопаснее это делать через ID группы. Почему безопаснее? Потому что при заполнении данными пользователь может случайно внести два раза название одной и той же группы. ID у них будут разными, а название одной и тоже. А если пользователи есть в одной и в другой группе, то при группировке по полю Группа пользователи обеих групп посчитаются вместе, что исказит результат. Но это только в данном случае.
Давайте теперь рассмотрим другой пример. Пусть у нас есть три таблицы: Группы товаров, Товары и Поступления. Выполним запрос на объединение данных из трех таблиц:
SELECT
группы.ID_группы,
группы.Название_группы,
товары.ID_товара,
товары.Наименование,
поступления.ID_поступления,
поступления.Дата_поступления,
поступления.Количество,
поступления.Цена,
поступления.Накладная
FROM
группы
INNER JOIN товары ON товары.ID_группы = группы.ID_группы
INNER JOIN поступления ON поступления.ID_товара = товары.ID_товара
И получим:
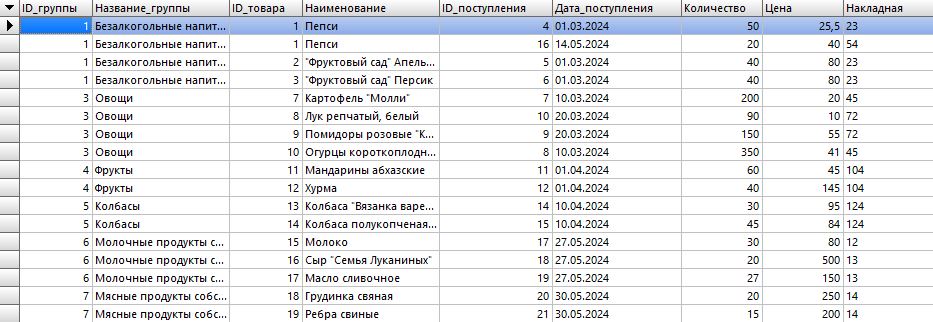
Мы видим, что у нас есть несколько групп товаров и у каждого товара есть цена. Давайте узнаем среднюю стоимость товаров по каждой группе:
SELECT
группы.ID_группы,
группы.Название_группы,
avg(поступления.Цена) AS Средняя_стоимость_группы
FROM
группы
INNER JOIN товары ON товары.ID_группы = группы.ID_группы
INNER JOIN поступления ON поступления.ID_товара = товары.ID_товара
GROUP BY группы.ID_группы
Результат:
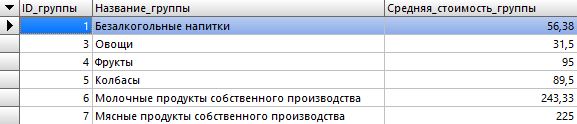
Мы получили устраивающий нас результат, но его можно улучшить, если провести сортировку по столбцу средней стоимости группы. Для этого сделаем так:
SELECT
группы.ID_группы,
группы.Название_группы,
avg(поступления.Цена) AS Средняя_стоимость_группы
FROM
группы
INNER JOIN товары ON товары.ID_группы = группы.ID_группы
INNER JOIN поступления ON поступления.ID_товара = товары.ID_товара
GROUP BY группы.ID_группы
ORDER BY AVG(поступления.Цена) ASC
Или запишем последнюю строку так:
... ORDER BY AVG(Средняя_стоимость_группы) ASC
В результате данные будут отсортированы по последнему столбцу.
Если взять еще не сгруппированную таблицу, то видно, что в каждой группе присутствую товары с разными ценами (по ним мы только что искали среднюю цену). А давайте теперь найдем товар, который имеет самую большую цену по своей группе:
SELECT
группы.ID_группы,
группы.Название_группы,
MAX(поступления.Цена) AS Максимальная_цена_по_группе
FROM
группы
INNER JOIN товары ON товары.ID_группы = группы.ID_группы
INNER JOIN поступления ON поступления.ID_товара = товары.ID_товара
GROUP BY группы.ID_группы
ORDER BY Максимальная_цена_по_группе ASC
Результат:
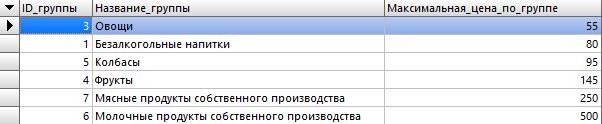
Агрегатная функция MIN выполнит аналогичное действие, только покажет самые минимальные значения по всем группам. Ну а SUM посчитает суммы по каждой группе.
Предложение WHERE в SELECT (подзапросы)
Давайте рассмотрим некоторые интересные особенности команды WHERE. И давайте ознакомимся с вложенными запросами. Для чего нужны вложенные запросы и что это такое? Вложенный запрос может быть вставлен в предложение WHERE или же в то место, где перечисляются поля. Рассмотрим оба случая. Сначала случай, когда вложенный запрос вставляется в предложение WHERE.
Итак, для чего это нужно? Иногда нам нужно в качестве условия для выборки данных указать ряд значений. Для этого у нас служит оператор IN. Например,
SELECT
группы_товаров.Код_группы,
группы_товаров.Группа,
товары.Код_товара,
товары.Товар,
стоимость_товаров.Стоимость,
стоимость_товаров.Дата_установления
FROM
группы_товаров
LEFT JOIN товары ON товары.Код_группы = группы_товаров.Код_группы
LEFT JOIN стоимость_товаров ON стоимость_товаров.Код_товара = товары.Код_товара
WHERE стоимость_товаров.Код_стоимости IN (1,2,4,23,39)
Здесь мы выбираем товары, код стоимости у которых принимает одно из перечисленных значений: 1,2,4,23 или 39. Можно вместо каждой из этих цифр подставить переменную, или, как ее называют в запросах — параметр. Но проблема заключается в том, что мы не знаем сколько цифр там будет — может две, может три или четыре...
Эту проблему можно решить двумя способами. Можно использовать в запросе в скобках вместо цифр или параметров — макроподстановку. Это хороший способ, но он зависит от языка программирования. Реализовывается макроподстановка по разному, а в некоторых языках программирования нет такого понятия, как макроподстановка.
Второй способ универсальный и выполняется он средствами самого SQL, то есть мы напишем подзапрос, например такой:
SELECT
группы_товаров.Код_группы,
группы_товаров.Группа,
товары.Код_товара,
товары.Товар,
стоимость_товаров.Стоимость,
стоимость_товаров.Дата_установления
FROM
группы_товаров
LEFT JOIN товары ON товары.Код_группы = группы_товаров.Код_группы
LEFT JOIN стоимость_товаров ON стоимость_товаров.Код_товара = товары.Код_товара
WHERE стоимость_товаров.Код_стоимости IN (SELECT MAX(стоимость_товаров.Код_стоимости)
FROM стоимость_товаров
GROUP BY стоимость_товаров.Код_товара)
На самом деле подзапрос может быть любым, который вам нужен. Единственное условие заключается в том, что в подзапросе выбираться должно одно поле таблицы, то есть между SELECT и FROM в подзапросе должно быть одно поле, иначе СУБД вернет вам ошибку.
Так что же мы делаем в этом запросе? Как его читать корректно? Читать такие запросы нужно с конца, то есть с подзапроса. В подзапросе у нас выбирается поде «Код стоимости» из таблицы «Стоимость товаров», но мы выбираем максимальное значение кода стоимости из группы. То есть результат выборки сгруппирован по коду товара и в каждой группе есть несколько записей с уникальным кодом стоимости. И вот мы в подзапросе выбираем из каждой группы по записи с ее максимальным кодом стоимости. Соответственно у нас получается одномерный массив данных, который и используется в качестве параметров оператора IN внешнего запроса.
Другой пример может быть таким:
SELECT
группы_товаров.Код_группы,
группы_товаров.Группа,
товары.Код_товара,
товары.Товар,
стоимость_товаров.Стоимость,
стоимость_товаров.Дата_установления
FROM
группы_товаров
LEFT JOIN товары ON товары.Код_группы = группы_товаров.Код_группы
LEFT JOIN стоимость_товаров ON стоимость_товаров.Код_товара = товары.Код_товара
WHERE стоимость_товаров.Код_стоимости IN (SELECT стоимость_товаров.Код_стоимости
FROM стоимость_товаров
WHERE стоимость_товаров.Код_стоимости>15)
Тот же внешний запрос, но внутренний поменялся. теперь во внутреннем запросе мы выбираем все записи с кодом стоимости больше 15 и получаем во внутреннем запросе снова одномерный массив, состоящий из одного столбца данных.
Вот еще небольшой пример:
SELECT *
FROM Поступление
WHERE Код_поставщика IN (SELECT Код_поставщика
FROM Поставщики
WHERE Наименование_поставщика LIKE "Полин%")
Здесь мы из таблицы «Поступление» выбираем записи (все столбцы), у которых код поставщика равен одному из перечисленных значений, определенный внутренней выборкой. В подзапросе же мы выбираем данные из справочника «Поставщики». И выбираем мы все записи, у которых наименование поставщика начинается со слова «Полин». То есть, в выборку попаду записи с названием «Полинка», «Полина» и т.п.
Давайте рассмотрим еще один интересный оператор, который используется в предложении WHERE. Это оператор NOT — отрицание.
SELECT * FROM Фотоальбомы WHERE NOT(Уровень_доступа="Приватный")
Здесь мы выбираем все записи из таблицы «Фотоальбомы», у которых уровень доступа не является приватным. То есть, в результат выборки попадут все записи, кроме записей с приватным уровнем доступа.
Теперь давайте пробежимся по датам. Вот эта запись:
SELECT Код_периода FROM Периоды WHERE Дата BETWEEN "2024-01-01" AND "2024-12-31"
и вот эта запись:
SELECT Код_периода FROM Периоды WHERE Дата >= "2024-01-01" AND Дата <= "2024-12-31"
являются абсолютно одинаковыми.
Далее. Есть такая интересная штука в запросах как псевдонимы имен полей. Для тех кто не знает это выглядит так:
SELECT
товары.Код_товара AS Код_товара_из_таблицы_Товары,
поступления.Код_товара AS Код_товара_из_таблицы_Поступления,
поступления.Количество,
поступления.Дата
FROM
...
Пусть это не очень удачный пример с точки зрения выбора полей в запросе, но зато он демонстрирует, что такое псевдонимы. Если бы их не было, то результирующую выборку бы у нас попало два поля, которые бы имели одинаковые названия полей, а именно «Код товара». Конечно СУБД бы подставила единичку к одному из них, но тем не менее. Псевдонимы же нам дают возможность задать те имена полей, которые мы хотели бы видеть.
Проблема в том, что WHERE не видит псевдонимов. Для этого вместо слова WHERE нужно использовать HAVING, например:
SELECT
марка.Название AS Название_марки
FROM Транспортные_средства
HAVING Название_марки = "Volkswagen"
Либо в WHERE потребуется повторить целиком выражение, которое использовалось для формирования поля, например:
SELECT
Concat(марка.Название , " ", модель.Название , " ", транспортные_средства.ГосНомер) AS Автомобиль
FROM Транспортные_средства
WHERE Concat(марка.Название , " ", модель.Название , " ", транспортные_средства.ГосНомер) LIKE "%Volkswagen%"
Здесь мы объединяем три столбца и получаем результирующий столбец — Автомобиль. Но нам не нужны все записи из таблицы, нам нужны только записи, у которых в этом результирующем столбце будет присутствовать фраза ""Volkswagen. Ну, либо, как упоминалось выше, сделать так:
SELECT
Concat(марка.Название , " ", модель.Название , " ", транспортные_средства.ГосНомер) AS Автомобиль
FROM Транспортные_средства
HAVING Автомобиль LIKE "%Volkswagen%"
Вообще HAVING используется совместно с группировкой и отличие WHERE от HAVING состоит в том, что предложение WHERE сначала сделает выборку данных, а затем будет эту выборку группировать и вычислять агрегатные функции, например такие, как SUM. Ну то есть, суммироваться будут не все значения поля, а только те, которые остались после выборки.
HAVING же сначала группирует, а уже затем к полученной группе применяет условия выборки и агрегатные функции.
Подзапросы SELECT в качестве выбора результирующего поля
Давайте теперь рассмотрим ситуацию, когда вложенный запрос находится не в предложении WHERE, а в области перечисления полей. Давайте сразу к примеру. Представьте себе, что у нас есть база данных из трех таблиц:
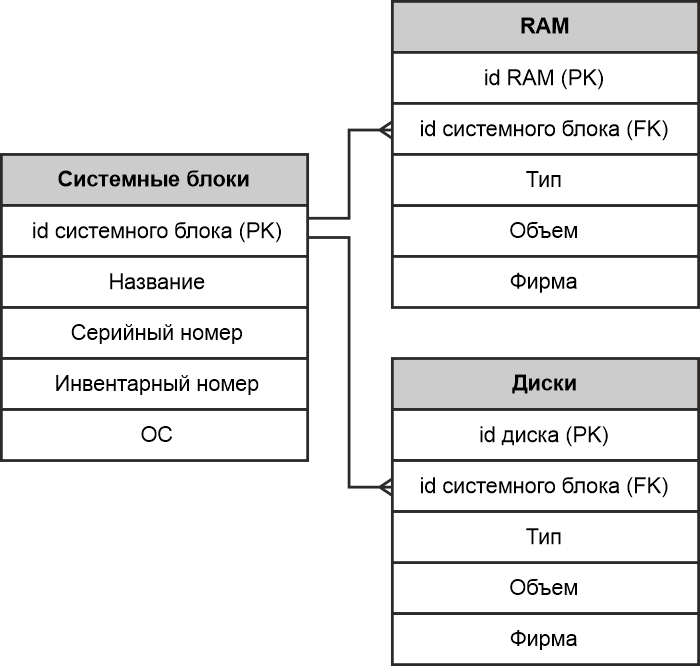
Что мы имеем? У нас есть простая база данных содержимого системного блока. В каждом системном блоке может быть установлено от одного до нескольких модулей оперативной памяти (RAM) и от одного до нескольких дисков. Соответственно, таблицы «RAM» и «Диски» являются дочерними.
Давайте посмотрим на значения, хранящиеся в этих таблицах. Таблица «Системные блоки» имеет следующие записи:
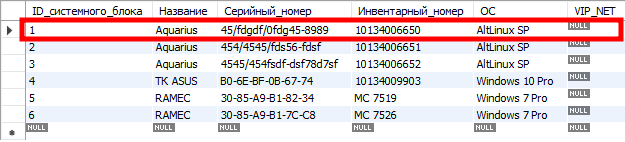
Таблица «RAM»:
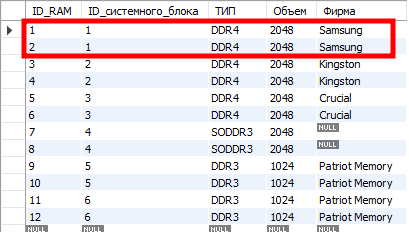
Таблица «Диски»:
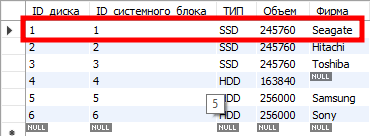
Возьмем из таблицы системных блоков самую первую запись. В таблице «RAM» мы увидим, что системному блоку с ID_системного_блока=1 соответствует две записи из таблицы «RAM», ну и одна запись из таблицы «Диски».
Давайте извлечем данные из этих таблиц с помощью запроса:
SELECT
системные_блоки.ID_системного_блока,
системные_блоки.Название,
системные_блоки.Инвентарный_номер,
Sum(ram.Объем) AS Общий_объем_RAM,
Sum(диски.Объем) AS Общий_объем_Диска
FROM
системные_блоки
INNER JOIN ram ON ram.ID_системного_блока = системные_блоки.ID_системного_блока
INNER JOIN диски ON диски.ID_системного_блока = системные_блоки.ID_системного_блока
GROUP BY системные_блоки.ID_системного_блока
Получился следующий результат:

И в итоге мы видим неверный результат. Общий объем дисков у нас в результате нашего запроса посчитался неверно. Должен быть всего 245760, а получился в два раза больше — 491520. Почему это произошло? Все очень и очень просто. Сумма у диска неверная, потому что в таблице «Диски» была всего одна запись диска, а у памяти две записи. И в результате объединения таблиц в запросе в результирующую выборку дописывается значение и у диска (хотя в таблице его нет). При этом оператор Sum ее считает. Смотрите, что будет, если мы уберем SUM и, соответственно, группировку тоже:
SELECT
системные_блоки.ID_системного_блока,
системные_блоки.Название,
системные_блоки.Инвентарный_номер,
ram.Объем AS Объем_RAM,
диски.Объем AS Объем_диска
FROM
системные_блоки
INNER JOIN ram ON ram.ID_системного_блока = системные_блоки.ID_системного_блока
INNER JOIN диски ON диски.ID_системного_блока = системные_блоки.ID_системного_блока
Результат:
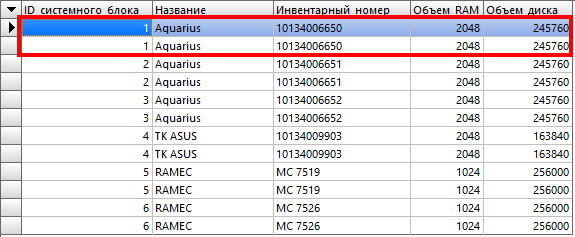
Видите что получается? В результате объединения таблиц мы видим, что у нашего системного блока с ID_системного_блока=1 присутствует два диска, а на самом деле то в таблице «Диски» он один. Это происходит потому что мы имеем две записи в таблице «RAM». А если бы имели три, то было бы затроение и так далее.
Причем, если бы дисков было больше, чем памяти, например три строки у дисков в таблице «Диски», а в таблице «RAM» две строки, то тогда бы в результирующем запросе добавлялась лишняя строка у памяти.
Что можно сказать? Выйти из ситуации можно следующим запросом:
SELECT
системные_блоки.ID_системного_блока,
системные_блоки.Название,
системные_блоки.Инвентарный_номер,
(SELECT
Sum(ram.Объем)
FROM системные_блоки
INNER JOIN ram ON ram.ID_системного_блока = системные_блоки.ID_системного_блока
GROUP BY системные_блоки.ID_системного_блока
HAVING ram.ID_системного_блока=системные_блоки.ID_системного_блока) AS Общий_объем_RAM,
(SELECT
Sum(диски.Объем)
FROM системные_блоки
INNER JOIN Диски ON Диски.ID_системного_блока = системные_блоки.ID_системного_блока
GROUP BY системные_блоки.ID_системного_блока
HAVING диски.ID_системного_блока=системные_блоки.ID_системного_блока) AS Общий_объем_диска
FROM
системные_блоки
INNER JOIN ram ON ram.ID_системного_блока = системные_блоки.ID_системного_блока
INNER JOIN диски ON диски.ID_системного_блока = системные_блоки.ID_системного_блока
GROUP BY системные_блоки.ID_системного_блока
А еще лучше, если мы используем вот такой запрос (для меня он даже предпочтительней):
SELECT
системные_блоки.ID_системного_блока,
системные_блоки.Название,
системные_блоки.Инвентарный_номер,
(SELECT SUM(ram.Объем)
FROM ram
WHERE ID_системного_блока=системные_блоки.ID_системного_блока
GROUP BY ram.ID_системного_блока) AS Общий_объем_RAM,
(SELECT SUM(диски.Объем)
FROM диски
WHERE ID_системного_блока=системные_блоки.ID_системного_блока
GROUP BY диски.ID_системного_блока) AS Общий_объем_Диска
FROM системные_блоки
GROUP BY системные_блоки.ID_системного_блока
А поскольку второй на мой взгляд лучше, давайте его и разберем, дабы не запутывать вас. А первый разберете сами, если будет желание. Что мы делаем? Мы выбираем три поля из таблицы «Системные блоки». А дальше мы в качестве полей мы пишем вложенные запросы. И в результате получаем правильный результат расчета:

Вот теперь мы уже видим, что у нашего системного блока объем диска как и положено — 245760 МБ.
Многоуровневая вложенность
Скажем так, что количество подзапросов не обязательно должно быть ограничено одним. Может быть вполне и такая конструкция (из моей практики):
SELECT
квр.Статья AS Статья_КВР,
косгу.Статья AS Статья_КОСГУ,
косгу.Название AS Название_КОСГУ,
квр_косгу.Код_КВР_КОСГУ,
виды_затрат.Код_затраты,
виды_затрат.Вид,
план.Код_плановой_суммы,
виды_затрат.Договор,
Coalesce(план.Сумма, 0) AS План,
Coalesce((SELECT SUM(суммы_по_видам_затрат.Сумма)
FROM суммы_по_видам_затрат
WHERE суммы_по_видам_затрат.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY суммы_по_видам_затрат.Код_плановой_суммы),0) AS Заключено_договоров,
if(виды_затрат.Договор = 'Да', план.Сумма - Coalesce((SELECT SUM(суммы_по_видам_затрат.Сумма)
FROM суммы_по_видам_затрат
WHERE суммы_по_видам_затрат.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY суммы_по_видам_затрат.Код_плановой_суммы),0),0) AS План_договор_остаток,
Coalesce((SELECT SUM(If(заявки.Статус = 'В обработке', заявки.Сумма, 0))
FROM заявки
WHERE заявки.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY заявки.Код_плановой_суммы),0) AS В_обработке,
Coalesce((SELECT SUM(If(заявки.Статус = 'Исполнена', заявки.Сумма, 0))
FROM заявки
WHERE заявки.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY заявки.Код_плановой_суммы),0) AS Исполнена,
if(виды_затрат.Договор = 'Да', Coalesce((SELECT SUM(суммы_по_видам_затрат.Сумма)
FROM суммы_по_видам_затрат
WHERE суммы_по_видам_затрат.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY суммы_по_видам_затрат.Код_плановой_суммы),0) - Coalesce((SELECT SUM(заявки.Сумма)
FROM заявки
WHERE заявки.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY заявки.Код_плановой_суммы),0),Coalesce(план.Сумма, 0)-Coalesce((SELECT SUM(заявки.Сумма)
FROM заявки
WHERE заявки.Код_плановой_суммы = план.Код_плановой_суммы
GROUP BY заявки.Код_плановой_суммы),0)) AS Остаток_по_договорам
FROM
квр
INNER JOIN квр_косгу ON квр_косгу.Код_КВР = квр.Код_КВР
INNER JOIN косгу ON квр_косгу.Код_КОСГУ = косгу.Код_КОСГУ
INNER JOIN виды_затрат ON виды_затрат.Код_КВР_КОСГУ = квр_косгу.Код_КВР_КОСГУ
LEFT JOIN план ON план.Код_затраты = виды_затрат.Код_затраты
WHERE план.Код_года=:Код_года
ORDER BY квр_косгу.Код_КВР_КОСГУ ASC, виды_затрат.Код_затраты ASC
Чтобы получить поле «Остаток по договорам» потребовалось четыре уровня вложенности.
Псевдонимы таблиц
Давайте рассмотрим еще одну крутую вещь — псевдонимы таблиц. Не полей, а именно таблиц.
И наверное опять сразу к примеру. На этот раз мы рассмотрим предметную область маршрутов движения автобусов. Рассмотрим мы конечно только ту часть базы данных, которая нам нужна для примера.

В схеме данных представлена классическая схема данных со связями один-ко-многим. Но вот интересный момент. У нас есть таблица «Направления» и в ней нам нужно указать пункт отправления и пункт назначения. И мы эти пункты должны быть из справочника. Ну так положено. И получается, что у нас на два поля используется один и тот же справочник? Можно ли так? Конечно можно. Нет никакой ошибки в том, что одно поле (id пункта) таблицы «Пункты» связано с двумя полями одной и той же таблицы «Направления».
Единственное, что здесь нам потребуется, так это правильно написать запрос на выборку из такой базы данных. Для этого нам потребуется из каждой таблицы: регионы, районы и пункты сделать по две таблицы. Но не физически, а виртуально. То есть, мы создаем из таблицы «Регионы» таблицу «Регион отправления» и «Регион прибытия». Из таблицы «Районы» мы создаем «Район отправления» и «Район прибытия» и аналогично с таблицей «Пункты».
Но то есть, мы могли бы использовать свои справочники для таблицы «Направления» отдельно для пункта отправления и для пункта назначения. Но это было бы неправильно, потому что справочники бы дублировались в базе данных и нам бы пришлось заполнять их одинаковыми данными. Например, мы бы имели две таблицы «Регион отправления» и «Регион прибытия» и мы должны бы их были заполнять одинаковыми значениями, ведь мы один и тот же регион может быть как местом отправки, так и местом прибытия. И это бы прекрасно работало бы, но это было бы не профессионально.
Более того, это бы привело еще и к неудобству работы, где нужно было бы по два раза вводить оду и туже информацию в справочник. Конечно это можно автоматизировать, но все=же это не профессионально. Поэтому мы сделаем так:
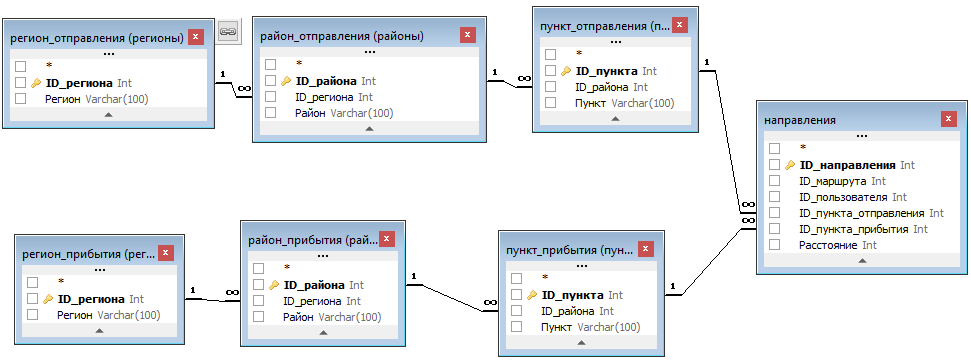
Но это не физические таблицы в базе. Таблиц в базе по прежнему осталось 4, а здесь мы видим 7 таблиц. Такого мы достигли благодаря запросу:
SELECT
регион_отправления.Регион AS регион_отправления,
район_отправления.Район AS район_отправления,
пункт_отправления.Пункт AS пункт_отправления,
регион_прибытия.Регион AS регион_прибытия,
район_прибытия.Район AS район_прибытия,
пункт_прибытия.Пункт AS пункт_прибытия
FROM
направления
INNER JOIN пункты пункт_отправления ON направления.ID_пункта_отправления = пункт_отправления.ID_пункта
INNER JOIN районы район_отправления ON пункт_отправления.ID_района = район_отправления.ID_района
INNER JOIN регионы регион_отправления ON район_отправления.ID_региона = регион_отправления.ID_региона
INNER JOIN пункты пункт_прибытия ON направления.ID_пункта_прибытия = пункт_прибытия.ID_пункта
INNER JOIN районы район_прибытия ON пункт_прибытия.ID_района = район_прибытия.ID_района
INNER JOIN регионы регион_прибытия ON район_прибытия.ID_региона = регион_прибытия.ID_региона
Результат будет следующим:
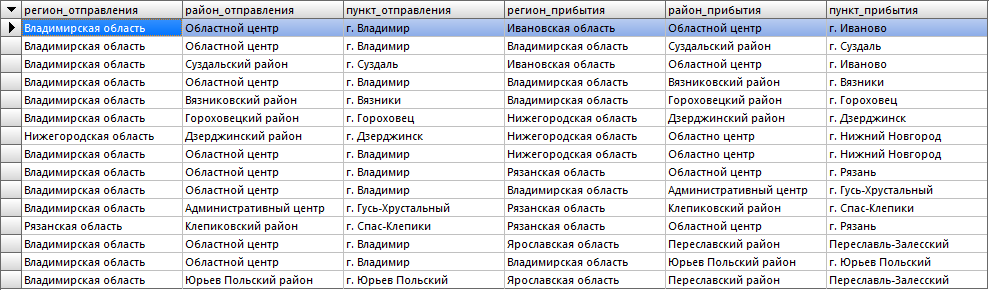
Мы видим, что у нас все правильно отобразилось. А вот если бы мы сделал без псевдонимов — вот так:
SELECT
регионы.Регион,
районы.Район,
пункты.Пункт,
направления.ID_пункта_отправления,
направления.ID_пункта_прибытия
FROM
регионы
INNER JOIN районы ON районы.ID_региона = регионы.ID_региона
INNER JOIN пункты ON пункты.ID_района = районы.ID_района
INNER JOIN направления ON направления.ID_пункта_отправления = пункты.ID_пункта AND
направления.ID_пункта_прибытия = пункты.ID_пункта
Тогда бы результат запроса у нас бы оказался пустым, потому что курсоры таблиц «Регионы», «Районы» и «Пункты» не знают, на какую запись им стать. С одной стороны курсор таблицы «Пункты» должен стать на запись, у которой ID пункта равен ID_пункта_отправления таблицы «Направления». С другой стороны он должен стать на запись, у которой ID пункта равен ID_пункта_прибытия таблицы «Направления». А он не может одновременно стоять на двух записях сразу. Поэтому такой запрос будет ошибочным.
Условные функции и форматирование полей в SELECT
Перейдем к следующей интересной теме — форматирование полей в запросах SELECT.
CONCAT
Давайте возьмем предыдущий пример. Я повторю его тут, чтобы не листать:
SELECT
регион_отправления.Регион AS регион_отправления,
район_отправления.Район AS район_отправления,
пункт_отправления.Пункт AS пункт_отправления,
регион_прибытия.Регион AS регион_прибытия,
район_прибытия.Район AS район_прибытия,
пункт_прибытия.Пункт AS пункт_прибытия
FROM
направления
INNER JOIN пункты пункт_отправления ON направления.ID_пункта_отправления = пункт_отправления.ID_пункта
INNER JOIN районы район_отправления ON пункт_отправления.ID_района = район_отправления.ID_района
INNER JOIN регионы регион_отправления ON район_отправления.ID_региона = регион_отправления.ID_региона
INNER JOIN пункты пункт_прибытия ON направления.ID_пункта_прибытия = пункт_прибытия.ID_пункта
INNER JOIN районы район_прибытия ON пункт_прибытия.ID_района = район_прибытия.ID_района
INNER JOIN регионы регион_прибытия ON район_прибытия.ID_региона = регион_прибытия.ID_региона
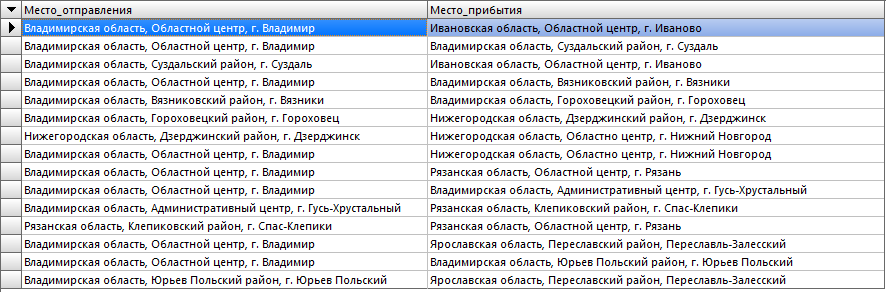
Давайте объединим несколько полей друг с другом. Для этого используется функция CONCAT.
SELECT
Concat(регион_отправления.Регион, ', ', район_отправления.Район, ', ', пункт_отправления.Пункт) AS Место_отправления,
Concat(регион_прибытия.Регион, ', ', район_прибытия.Район, ', ', пункт_прибытия.Пункт) AS Место_прибытия
FROM
направления
INNER JOIN пункты пункт_отправления ON направления.ID_пункта_отправления = пункт_отправления.ID_пункта
INNER JOIN районы район_отправления ON пункт_отправления.ID_района = район_отправления.ID_района
INNER JOIN регионы регион_отправления ON район_отправления.ID_региона = регион_отправления.ID_региона
INNER JOIN пункты пункт_прибытия ON направления.ID_пункта_прибытия = пункт_прибытия.ID_пункта
INNER JOIN районы район_прибытия ON пункт_прибытия.ID_района = район_прибытия.ID_района
INNER JOIN регионы регион_прибытия ON район_прибытия.ID_региона = регион_прибытия.ID_региона
DATEDIFF
Как посчитать количество дней между двумя датами в запросе Select? Ответ прост — использовать функцию DATEDIFF. Пример:
SELECT задачи.ID_задачи, задачи.Название, задачи.Срок_с, задачи.Срок_по, DATEDIFF(задачи.Срок_по,задачи.Срок_с) AS Количество FROM задачи
В данном запросе мы выводим список задач. У каждой задачи есть срок выполнения «с» и срок выполнения «по». Например, нам нужно выполнить какую-то задачу с 11.12.2024 по 25.12.2024. И нам нужно посчитать, сколько дней будет в этом диапазоне. Для этого как раз и предназначена данная функция.
CAST
Для объединения полей разных типов используется функция преобразования типов данных, например, CAST. Допустим у нас есть Классы в школе: 1А, 1Б, 1В, 2А, 2Б и т.п. И допустим, что номер класса хранится одной таблице, а литера класса в другой. То есть, есть две таблицы: «Номер» и «Литера», связь между которыми один-ко-многим. В названии класса присутствует цифра и буква. Это два разных типа данных. И они хранятся, как сказано, в разных таблицах. Выглядит это так:
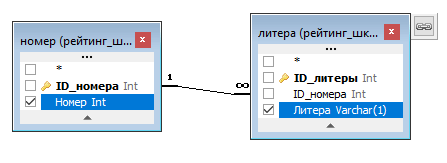
Соответственно запрос такой:
SELECT
номер.Номер,
литера.Литера
FROM
номер
INNER JOIN литера ON литера.ID_номера = номер.ID_номера
В результате выполнения запроса получается простая таблица:
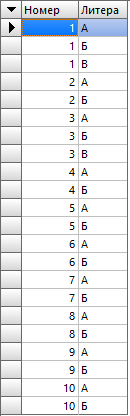
Первый столбец у нас с типом INTEGER, а второй — VARCHAR. Давайте приведем поля к одному типу и объединим их в один столбец:
SELECT
CONCAT(cast(номер.Номер as char),' ', литера.Литера) as Класс
FROM номер INNER JOIN литера ON литера.ID_номера = номер.ID_номера
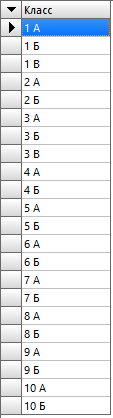
Сначала мы выполняем преобразование значений поля «Номер» из INTEGER в VARCHAR с помощью функции CAST. А затем уже мы выполняем объединение полей с помощью ранее рассмотренной функции CONCAT. Результат будет таким:
DATE_FORMAT — форматирование даты и времени в запросе SELECT
Часто в результате выполнения запросу нужно отформатировать дату и время. Например для того, чтобы корректно отобразить ту же саму дату. Ведь в MYSQL дата отображается вот так: 2024-12-11. Но мы то с вами привыкли к тому, что она должна отображаться вот так: 11.12.2024. Для такого форматирования используем функцию DATE_FORMAT.
DATE_FORMAT(ФИО.Дата_рождения, '%d.%m.%Y') AS Дата_рождения
Эта функция форматирует не только дату, но и время. Чтобы привести его к виду 13:25 нужно записать:
DATE_FORMAT(смены.Время_открытия, '%H:%i')) AS Открытие
Тут еще стоит отметить, что при форматировании дата и время сразу приводятся к строковому типу данных (VARCHAR) без дополнительного преобразования. Если требуется соединить строку и дату, то это можно сделать следующим образом:
Concat(владелец.ФИО, ' ', cast(DATE_FORMAT(владелец.Дата_рождения, '%d.%m.%Y') as char)) AS ФИО_и_дата,
Можно объединить дату и время в один столбец, если они хранятся в разных:
Concat(DATE_FORMAT(смены.Дата_открытия, '%d.%m.%Y'), ' ', DATE_FORMAT(смены.Время_открытия, '%H:%i')) AS Открытие
ROUND — округление
Когда нам нужно округлить значение поля в результате запроса, то мы можем использовать функцию ROUND.
SELECT
....
ROUND(AVG(оценка),2) AS средняя_оценка
FROM
....
Это фрагмент гипотетического запроса, где мы с помощью функции AVG определяем среднее значение по полю «Оценка» и полученный результат округляем с помощью функции ROUND. Цифра «2» означает, что после запятой мы получим два знака. Если поставить нуль, то мы получим, соответственно, целое округленное число.
COALESCE — замена NULL нулем или другим значением
Чтобы заменить пустое значение нулем или другим значением существует два метода (по крайней мере, которые мне известны). Первый:
COALESCE(отгрузка.Количество, 0)
Здесь мы все пустые значения по полую «Количество» заменяем на нули.
Второй:
CASE WHEN отгрузка.Количество IS NULL THEN 0 ELSE отгрузка.Количество END
Здесь все ровно тоже самое. Только мы проверяем в запросе, что если значение поля «Количество» у нас пустое (IS NULL), то мы заменяем это значение на нуль, иначе (ELSE) показывается то количество, которое фактически имеется в таблице. Теперь пример:
SELECT
группы_товаров.Группа,
товары.Код_товара,
товары.Товар,
товары.Номенклатурный_номер,
единицы_измерения.Единица_измерения,
товары.Фотография,
поступление.Код_поступления,
поступление.Номер_партии,
поступление.Количество AS Поступило,
отгрузка.Код_отгрузки,
SUM(CASE WHEN отгрузка.Количество IS NULL THEN 0 ELSE отгрузка.Количество END) as Отгружено_способ_1,
SUM(COALESCE(отгрузка.Количество, 0)) as Отгружено_способ_2,
(поступление.Количество)-SUM(COALESCE(отгрузка.Количество, 0)) AS Остаток
FROM
единицы_измерения
INNER JOIN товары
ON товары.Код_единицы_измерения = единицы_измерения.Код_единицы_измерения
INNER JOIN группы_товаров
ON товары.Код_группы = группы_товаров.Код_группы
INNER JOIN поступление
ON поступление.Код_товара = товары.Код_товара
LEFT JOIN отгрузка
ON отгрузка.Код_поступления = поступление.Код_поступления
GROUP BY поступление.Код_поступления
В этом запросе мы поле «Отгружено» получаем двумя способами: с использованием COALESCE и с использованием конструкции CASE WHEN.
Условия IF в запросе
Сразу пример:
if(значения.Фактическое > Значения.Плановое, значения.Фактическое - Значения.Плановое,0) AS Разница
Если значение поля «Фактическое» больше значения поля «Плановое», то вычисляется разница, иначе показывается нуль.
Другой пример:
SELECT SUM(If(заявки.Статус = 'В обработке', заявки.Сумма, 0) AS В_обработке FROM заявки WHERE заявки.Код_плановой_суммы = план.Код_плановой_суммы GROUP BY заявки.Код_плановой_суммы
Здесь, например, проверяется поле «Статус» и, если оно «В обработке», то в этом поле выводится сумма из таблицы «Заявки». Если статус имеет другое значение, то в поле ставится нуль.
Причем результат группируется по коду плановой суммы и каждая группа суммируется по полю «заявки.Сумма». Ну то есть, получается, что мы группируем и суммируем только значения, у которых статус = «В обработке». Результирующему полю даем название «В обработке».
Вообще в SQL очень много функций и операторов и все я их здесь не рассмотрю. Давайте еще парочку для примера и будем закругляться.
DATE_ADD
На мой взгляд очень интересная функция. Что она делает? Данная функция добавляет интервал к дате. Что это и как это? Например, мне однажды понадобилось выводить сообщение для пользователя, которое предупреждает его об окончании срока действия ЭЦП за ранее (за несколько дней). Давайте посмотрим на формат этой функции:
DATE_ADD(<начальная дата>, <интервал> <тип интервала>)
Ну и сразу взглянем на пример, чтобы легче понять:
DATE_ADD('2024-12-13', 5 DAY) as TestDate
Здесь я к дате 13.12.2024 прибавляю 5 дней и результат отражается в поле TestDate. Ну а потом значение этого поля я сравню с текущей датой или с той, которая мне нужна и получу разницу.
Или вот еще пример:
DATE_ADD(curdate(), INTERVAL учет_эцп.Кол_дней_до_окончания DAY) as TestDate
Здесь функция curdate () возвращает нам текущую дату. То есть, в функцию DATE_ADD я передаю текущую дату как отправную точку, а в качестве интервала я передаю значение поля «Количество дней до окончания». Ну и DAY нам говорит о том, что интервал я буду считать в днях.
Эту функцию можно вставлять и в условия WHERE:
WHERE (DATE_ADD(curdate(), INTERVAL учет_эцп.Кол_дней_до_окончания DAY)>учет_эцп.Дата_окончания_действия) and (учет_эцп.Действие="Напоминать")
Здесь как раз, к текущей дате прибавляется количество дней, указанное в «Количество дней до окончания» и результат сравнивается со значением поля «Дата окончания действия». Также в выборку попадут записи, у которых значение поля «Действие» равняется «Напоминать».
Комментарии в тексте запроса
Комментарии в тексе запросе SQL делаются очень легко. Для этого достаточно добавить два подряд идущих прочерка: — или знака #.
SELECT CONCAT(cast(номер.Номер as char),' ', литера.Литера) as Класс --FROM номер INNER JOIN литера ON литера.ID_номера = номер.ID_номера
SELECT CONCAT(cast(номер.Номер as char),' ', литера.Литера) as Класс #FROM номер INNER JOIN литера ON литера.ID_номера = номер.ID_номера
Строка FROM выполняться не будет. А многострочный комментарий оформляется вот так:
SELECT /*CONCAT(cast(номер.Номер as char),' ', литера.Литера) as Класс FROM номер INNER JOIN литера ON литера.ID_номера = номер.ID_номера*/
Ну вот мы и подошли к окончанию статьи. Конечно про SELECT можно написать еще штук 15 таких статей и, скорее всего, материал будет не полным.
Здесь я просто постарался показать ответы на вопросы, которые раньше сам искал на просторах сети и в книгах, ну а потом практиковал.
Ну в дальнейшем мы конечно тоже будем много раз касаться различных запросов и то, как их оформлять на языке программирования.





