





































Этапы проектирования базы данных проектирования базы данных является важной составляющей частью разработки приложения. Неудачно разработанная база данных обязательно доставит определенные проблемы в будущем.
Добавление каких-либо функций в приложение может потребовать увеличения числа таблиц в базе данных. При неправильном подходе и неудачном проектировании дальнейшее развитие базы данных и приложения могут стать затруднительными. Для этих целей необходимо уделить тщательное внимание этапам проектирования базы данных.
Проектирование базы данных в общем случае делится всего на две части, а именно, на:
- логическое проектирование БД;
- физическое проектирование БД.
Логическое проектирование БД
Логическое проектирование никак не связано ни с каким типом СУБД, а потому его удобно делать на бумаге, а можно использовать для этих целей и специальные приложения. Но мне лично удобно черновой вариант будущей базы данных делать на бумаге карандашом. Это позволяется стирать, зачеркивать, добавлять нужные элементы, да и вообще быстро все переделывать, если мне просто что-то не понравится.
Затем уже, когда макет базы данных примет окончательный вид, можно будет сделать ее красивый чертеж с помощью одного из графических пакетов или специализированных программ. Также можно использовать такие программы как MS Visio. Но я предпочитаю использовать CorelDraw или Adobe Illustrator. И та и другая являются профессиональными графическими пакетами, а потому чертежи любого уровня в них также можно делать, как и в любой другой программе.
Давайте посмотрим на последовательность этапов логического проектирования базы данных
Сбор данных предметной области
Первым делом, что вам нужно сделать — это хорошенько изучить предметную область, которую вы собираетесь автоматизировать. Например, если это автоматизация склада, вам нужно детально изучить его работу и хорошо себе представлять все его операции. Как склад учитывает своих поставщиков и клиентов, которым он отгружает товар, оптовый это склад или нет, какими документами оформляются операции прихода и отгрузки товаров со склада и многие другие элементы учета.
В общем вам нужно будет хорошенько и досконально изучить каждую деталь работы вашей предметной области.
Концептуальное проектирование БД
Результатом концептуального проектирования БД будет являться концептуальная модель данных. А еще ее называют инфологической моделью данных, а концептуальное проектирование — инфологическим. так что это синонимы. Такую модель необходимо разработать уже после того, как вами будет изучена предметная область, то есть, выполнен первый этап проектирования базы данных, потому что сама по себе концептуальная модель данных создается на основании изученной предметной области.
Чтобы получить концептуальную модель данных необходимо также последовательно пройти через несколько этапов проектирования:
- определение сущностей;
- определение видов связей между сущностями;
- построение модели на уровне сущностей;
- определение первичных ключей;
- построение модели на уровне ключей;
- определение атрибутов сущностей (имена будущих полей);
- создание ER-модели данных предметной области;
- создание информационно-логической модели данных.
Определение сущностей
На изученной предметной области определяются будущие таблицы. Они еще не являются таблицами, поскольку у них нет нужных атрибутов (полей), потому называются они сущностями. Давайте возьмем для примера не склад, а более простую область. Пусть это будет прогнозирование заболеваний. Например, мы хорошо изучили все по этому предмету.
Какие у нас могут быть сущности. Можно выделить следующие:
- виды заболеваний. Для группировки заболеваний по видам. Так удобнее;
- заболевания. Собственно — эта сущность будет являться справочником заболеваний;
- периоды. Сущность будет являться справочником периодов для ведения статистики;
- статистика. Сущность, предназначенная для статистики заболеваний;
- пользователи. Эта необязательная сущность. Но можно ее использовать, например, для того, чтобы в статистике отражалось, какой из пользователей добавлял показатель.
Все, сущности мы определили, теперь нам нужно определить виды связей между сущностями и построить модель на уровне сущностей.
Виды связей между сущностями
Давайте попробуем определить пока словесно виды связей между перечисленными сущностями. Если вы не знаете, какие виды связей бывают, вы можете ознакомиться с ними в статье «Виды связей между таблицами».
Давайте посмотрим на две сущности «Виды заболеваний» и «Заболевания». Как их можно связать между собой?
Одному виду заболеваний будет соответствовать несколько заболеваний. Например, вид заболеваний — сердечные. Соответственно к сердечным относится множество заболеваний: аритмия, гипертония, инфаркты разной степени и прочие заболевания. Следовательно, связь между этими сущностями будет один-ко-многим, где сущность «Виды заболеваний» будет являться главной (родительской), а «Заболеваний» — подчиненной (дочерней).
Статистика у нас ведется по заболеваниям. То есть, заболевания у нас будет справочной сущностью. Значит она будет являться родительской для сущности «Статистика».
У нас остались не связаны две сущности в базе «Пользователи» и «Периоды». Давайте с ними тоже поработаем. Сразу хочу отметить, что бывает так, что в базе может находиться сущность абсолютно не связана ни с какой другой таблицей. Так бывает не часто, но бывает. Просто надобности в связи такой сущности с другими сущностями нет.
Но мы свяжем наши сущности. Сущность «Периоды» будет являться главной по отношению к сущности «Статистика», между которыми будет связь один-ко-многим. Потому что один и тот же период времени будет участвовать множество раз в сущности «Статистика» при ведении статистики для разных заболеваний.
И последняя сущность «Пользователи». Каждый пользователь многократно может добавлять показатели статистики, следовательно, между ними также присутствует связь один-ко-многим, где сущность «Пользователи» является главной, а сущность «Статистика» — подчиненной.
Модель на уровне сущностей
А вот теперь, после нашего словесного описания покажем все это не рисунке, который называется моделью сущность-связь.
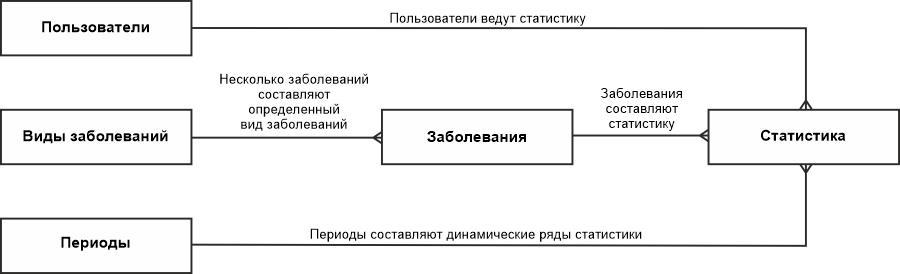
Как видно из рисунка — теперь у нас есть с вязи между сущностями, но как это связывается — приведенная схема нам не дает такой информации. Поэтому следующим этапом проектирования базы данных является определение первичных ключей у каждой сущности.
Определение первичных ключей
Итак, у нас пять сущностей в модели. Давайте у каждой сущности определим первичный ключ.
Первичный ключ — это поле (атрибут), каждое значение которого является уникальным в пределах сущности. Это если сказать простыми словами. Обозначается первичный ключ как PK (Ptimary key).
Первичный ключ обычно удобно делать просто автоинкрементным. Лично я так и делаю. Давайте определим ключи для наших сущностей:
| Сущность | Первичный ключ (PK) |
| Пользователи | Код пользователя |
| Виды заболеваний | Код вида |
| Заболевания | Код заболевания |
| Периоды | Код периода |
| Статистика | Код статистики |
Теперь нам требуется построить модель на уровне ключей.
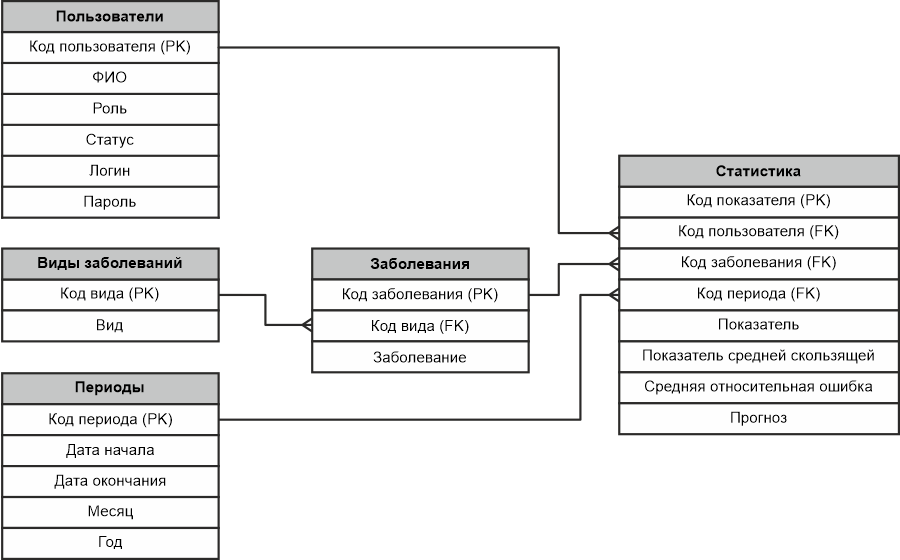
Модель на уровне ключей
Созданные первичные ключи должны быть соединены с какими то другими атрибутами (полями) других сущностей. Такие другие поля, с которыми соединяются первичные ключи называются внешними ключами (foreign key) и обозначаются FK.
Внешний ключ находится в подчиненной таблице, а первичный в главной. Внешний ключ может иметь точно такое же название как и первичный ключ, а может отличаться.
Первичный и внешний ключи могут быть как простыми, так и составными. Простой ключ состоит из одного поля, а составной из нескольких. Давайте на составных останавливаться не будем, поскольку в моей практике я как то легко обходился и без них. Я думаю, что это не такой частый случай.
А вот простые ключи — это каждодневная практика при проектировании баз данных.
Итак, на предыдущем этапе с первичными ключами мы определились, теперь посмотрим, как выглядит модель данных на уровне ключей:
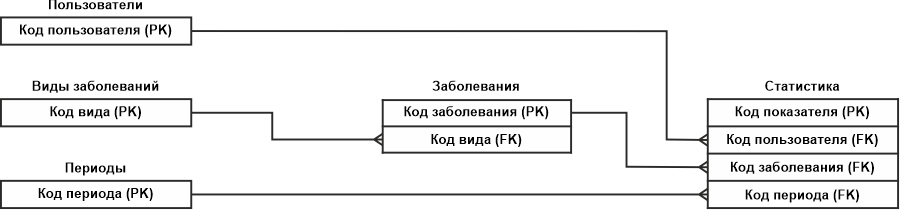
Модель на уровне ключей уже более или менее похожа информационно-логическую модель данных. Что можно увидеть на этой модели? Здесь показаны все те же наши пять сущностей. В каждой сущности имеются первичные ключи (PK), а в подчиненных (дочерних) сущностях — внешние ключи (FK).
Теперь мы можем перейти к следующему этапу проектирования базы данных, где мы добавим атрибуты к нашим объектам-сущностям.
Атрибут сущности — это обыкновенное поле будущей таблицы, если говорить простым языком.
Определение атрибутов сущностей
Давайте определим атрибуты для сущностей. Для определения атрибутов сущностей нам нужно понимать, что мы будем хранить в каждой из сущностей. Давайте рассмотрим каждую из пяти сущностей по отдельности.
Пользователи
В сущности «Пользователи» мы можем хранить следующую информацию:
- ФИО;
- Роль;
- Статус;
- Логин;
- Пароль.
Перечисленные позиции и будут являться нашими атрибутами. В атрибуте статуса можно хранить информацию о том, действующий ли это пользователь или нет.
Виды заболеваний
В этой сущности будем хранить только один атрибут:
- Вид.
Заболевания
В данной сущности также будем для простоты хранить только один атрибут, который будет содержать наименование заболевания. Назовем его:
- Заболевание
Периоды
В данной сущности будем хранить следующие атрибуты:
- Дата начала;
- Дата окончания;
- Месяц;
- Год.
В атрибуте «Месяц» мы будем хранить название месяца, а в атрибуте «Год» — цифру года. Тогда в атрибутах «Дата начала» и «Дата окончание» будем хранить даты периода. Например, месяц — Апрель, год — 2025, дата начала — 01.04.2025, дата окончания — 30.04.2025. То есть, месяц и год — это как бы названия нашего периода.
Статистика
Для данной сущности мы можем определить, например, такие атрибуты:
- Показатель;
- Показатель средней скользящей;
- Средняя относительная ошибка;
- Прогноз.
Создание ER-модели данных предметной области
ER-модель – это общее представление данных, ER-диаграмма – представление модели, а нотация – графический язык для представления модели. Создание модели ER можно осуществить в одной из нотации: IDEF1X, нотация Чена и нотация Мартина. И это уже непосредственный этап перед формированием окончательной информационно-логической модели данных.
Есть еще EER-модели данных с диаграммами EER. Это более расширенная по возможностям модель по отношению к ER. Но мы остановимся на ER, которой нам хватит с головой. EER же расширяет эту модель в плане наличия связи много-ко-многим. Поскольку в EER может быть описана промежуточная сущность, объединяющая в себе внешние ключи двух других родительских таблиц, между которыми бы нужно было бы установить связь много-ко-многим, но по техническим причинам этого сделать невозможно. В виду этого и появляется третья таблица, объединяющая в своих внешних ключах первичные ключи двух главных таблиц. Вот собственно и все по большому счету.
Ну если, в двух словах, то в ER нет возможности отобразить связь много-ко-многим, а в EER — есть. Прочитать о таком виде связи можно в статье «Виды связей между таблицами». Можно сказать, что EER — это более модернизированная ER, которая на практике более значима.
Итак, давайте рассмотрим то, как наша модель может выглядеть в разных ER нотациях:
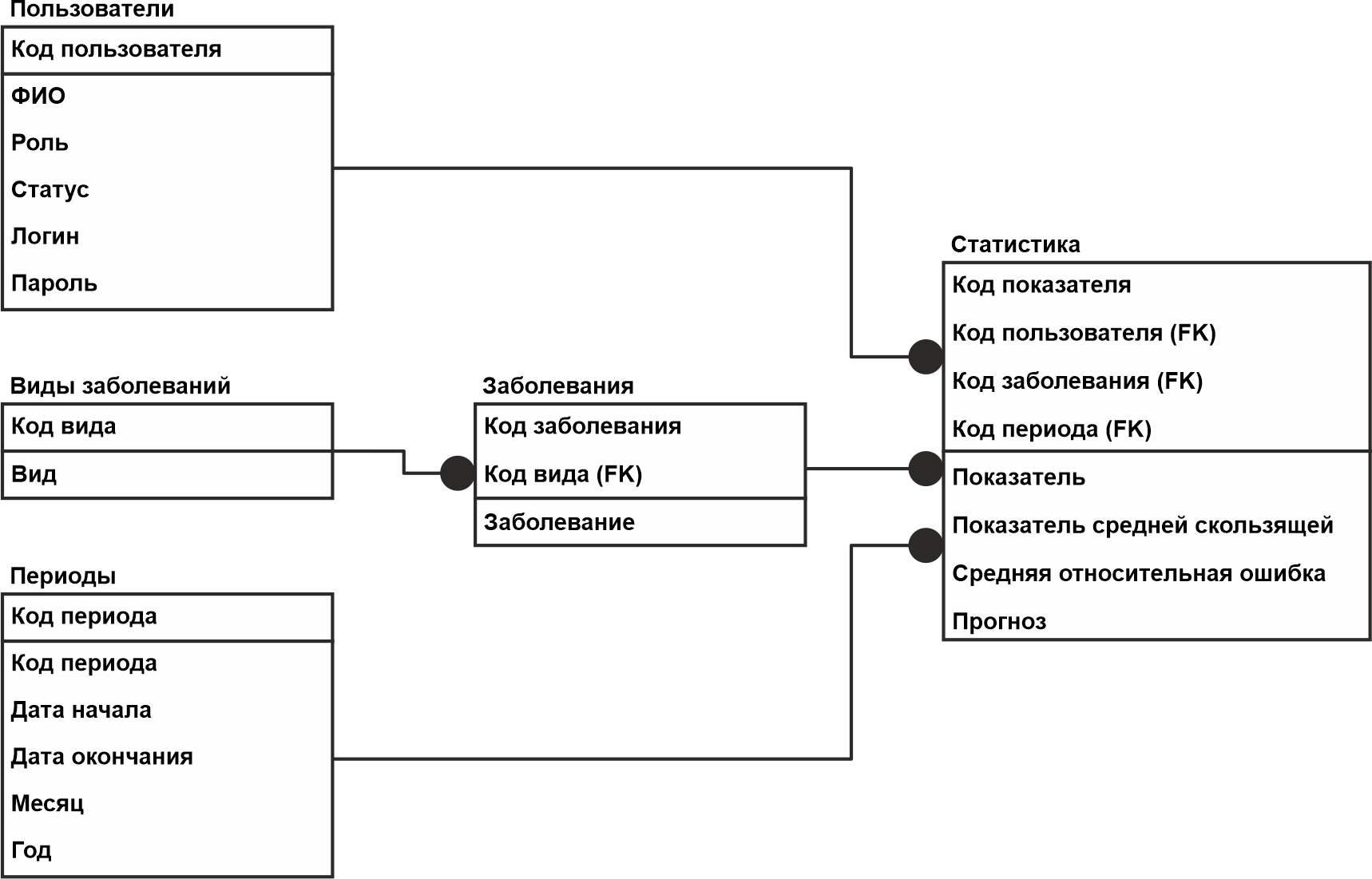
IDEF1X
Не будем вдаваться в подробность «А кто ее придумал», а сразу покажем ее на картинке:
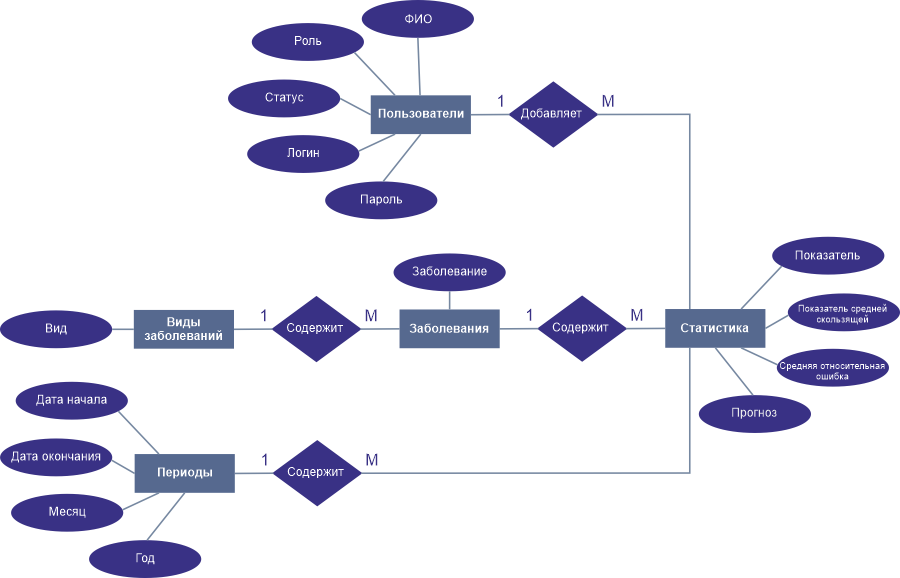
Нотация Чена
Еще одна интересная нотация, которая, как и предыдущая, представляет маленький практический интерес — с моей точки зрения. Но, она необходима, например для студентов, которым нужно написать ВКР или диссертацию, а потому мы тоже покажем как она выглядит.
Хотя читал статьи других авторов, которые утверждают, что данная нотация часто используется при проектировании БД. Может быть так и есть, не берусь говорить, но я ей как таковой не пользуюсь.
Нотация Мартина
Диаграмма в нотации Мартина выглядит как на рисунке ниже.
В принципе, все три нотации показывают одну и туже картину, просто выглядит каждая из них немного иначе. Я не использую ни одну из данных нотаций. Я вообще сразу логическое проектирование БД начинаю с этапа построения информационно-логической модели данных.
Информационно-логическая модель данных
На этом этапе создается информационно-логическая модель данных. Мне кажется — это самый интересный этап проектирования БД (конечно для тех людей, кому нравится проектировать базы данных). Вообще цель логического проектирования базы данных состоит в том, чтобы привести модель к четвертой нормальной форме, при которой полностью исключается вся избыточная информация.
Здесь как бы происходить преобразование всех предыдущих концептуальных моделей данных, которые были рассмотрены ранее в этой статье в информационно-логическую (или по простому, в логическую). Построение информационно-логической модели данных является последним этапом в разработке концептуальной модели данных. Дальше идет уже создание физической модели.
Причем знаете, что я заметил? Изучая книги и учебные материалы по логическому проектированию БД, я увидел, что в каждой из этих книг совершенно по разному представляется последовательность проектирования, а также одни и те же диаграммы имею разные названия нотаций в разной литературе. Или одни и те же диаграммы по разному выглядят в разных учебных материалах. Взять хотя бы нотацию Мартина. В разных книгах, страницах блогов и учебных материалов университетов и других учебных заведений — везде вы найдете отличия. Короче, все кувырком.
И в связи с этим, мне стало интересно, а какова же правильная последовательность всей этой разработки? Ну в итоге я истины так и не нашел. Но попытался в этой статье рассказать, как мне кажется, наиболее правильный порядок действий.
Конечно, некоторые этапы в книгах разбиваются ан еще более мелкие составляющие, но я это не стал описывать — это вообще уже совсем излишние вещи.
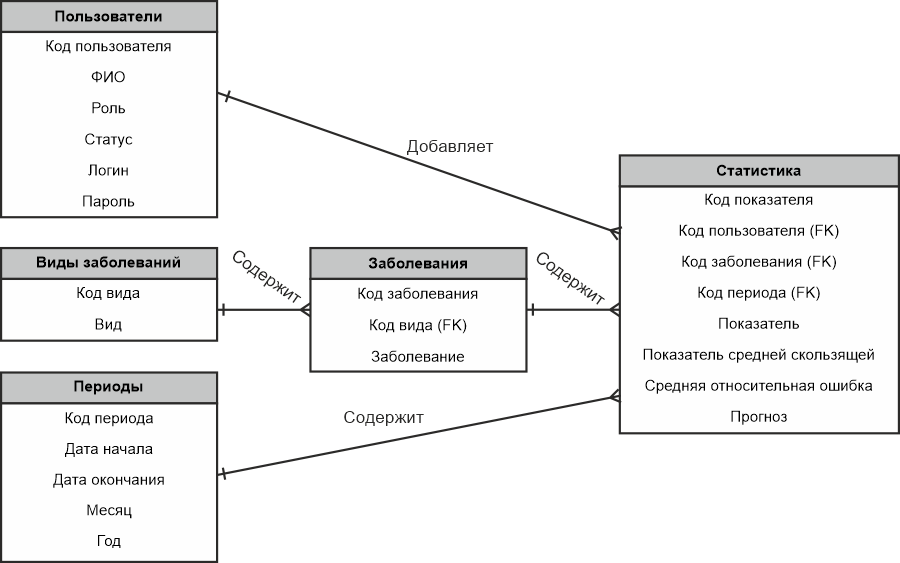
Давайте посмотрим сразу на нашу информационно-логическую модель данных:
На мой взгляд — это самая правильная и адекватная модель данных. Здесь все четко видно, видно какое поле с каким связано, каким типом связи оно связано. Чем не благодать?
Физическое проектирование БД
Все, с логическим проектированием мы закончили. Теперь можно проектировать физическую БД. Здесь особо писать не о чем. Следует только разъяснить, что физическое проектирование базы данных — это проектирование, которое зависит от конкретно выбранной СУБД.
То есть, на основе логической модели данных, не привязанной ни к какой СУБД мы открываем средство создания базы данных и создаем таблицы, поля и атрибуты этих полей.
Все СУБД хоть и похожи, но разные. Например, типы полей разные, разные условия наименования этих полей. Где то можно писать русскими буквами, где то не желательно. И вот эти то все нюансы и учитываются при проектировании физической базы данных.
Ну если брать, как пример, MySQL, то в ней мы проектируем либо скриптом вручную, либо используем одну из программ визуальной работы с БД. Я предпочитаю Workbench. Раньше мне еще нравилась программа dbForge. Ну и в зависимости от выбранной СУБД она называется немного по разному. Для той же MySQL она называется dbForge Studio for MySQL.
Она немножко тяжеловата, но зато у нее побольше всяких функций.
В настоящее время я использую для работы сочетание двух бесплатных программ: Workbench и FlySpeed SQL Query. Последняя — для визуального построения запросов. Очень удобная.
Единственное, чтобы я хотел еще сказать, так это то, что физическое проектирование — это фактически даталогическая модель данных. Хотя, если вы введете в поисковике, отличаются они или нет, то получите ответ, что это не одно и то же.
Скорее всего, такой ответ получается из-за того, что под физической модель данных понимается непосредственная реализация базы данных на жестком диске.
Но я с этим не согласен, ведь реализация — это не модель, а собственно, реализация по модели. А по какой модели? Получается по даталогической (физической).
Ну в общем то эти понятия практически тождественны, но все же между ними есть тонкая грань. Поэтому помните о том, что это фактически одно и тоже, если сильно не вдаваться в подробности! :)))





