





































В этой статье мы рассмотрим особенности работы с удаленными базами данных. Удаленные базы данных представляют собой модель, при которой приложение, обрабатывающее базу данных и база данных находятся на разных компьютерах сети.
Архитектура «Файл-сервер»
Удаленные базы данных построены по технологии «Клиент-сервер». Но для ее рассмотрения нужно кратко ознакомиться с архитектурой «Файл-сервер».
Следует начать с того, что существует понятие локальной базы данных (в противовес удаленной). Локальная база данных — это база данных, которая находится на одном компьютере сети вместе с ее обрабатывающим приложением. И для разработки локальной базы данных используются локальные (настольные) СУБД.
Примерами таких СУБД являются: MS Access, Paradox, FoxPro и другие.
Вообще, локальную базу данных тоже можно использовать по сети — для общего доступа. Для этого нужно будет на каком-нибудь компьютере сети (назовем его сервером) разместить базу данных и обрабатывающее ее приложение, а на всех остальных компьютерах сети просто запускать через сеть это самое размещенное на сервере приложение. В этом случае запуститься его копия.
Конечно совсем не обязательно устанавливать приложение только лишь на сервере. Его можно установить и на всех компьютерах сети, на которых будет осуществляться работа. В этом случае приложению следует указать путь к базе данных, которая находится на сервере.
Конечно же такой вариант не будет называться клиент-сервером, несмотря на то, что физически база данных является удаленной. Название этой архитектуры «Файл-сервер».
Какое же достоинство у этой архитектуры? Достоинством является простота разработки. Здесь создается база данных и приложение, а потом они используются в сетевом варианте. Для взаимодействия с базой данных в этом случае не нужно никакое дополнительное программное обеспечение. Но у этой архитектуры есть и серьезные недостатки:
- навигационный способ доступа к данным. То есть, если необходимо выбрать данные из определенной таблицы или группы таблиц, то эти данные будут целиком загружены в приложение и уже приложение будет вести их обработку. При этом в сети будет циркулировать огромное количество данных, что при большом количестве пользователей и активной работе существенно может снизить производительность сети;
- потребуется обязательно синхронизировать работу каждого пользователя. Это связано с блокировкой тех записей, которые обрабатывает другой пользователь;
- также существенным недостатком является то, что при такой архитектуре приложение не только обрабатывает данные, но и управляет базой данных. Поскольку управление осуществляется в этом случае с нескольких компьютеров, то в этом случае затрудняется поддержка целостности данных.
Ввиду обозначенных недостатков архитектура «Файл-сервер» применяется тогда, когда число пользователей базы данных не велико. Для построения систем с большом количеством пользователей, потребуется обратиться к клиент-серверной архитектуре.
Архитектура «Клиент-сервер»
В клиент-серверной архитектуре база данных размещается на отдельном компьютере сети, называемом сервером, сервером сети или просто — удаленным сервером. Само-собой, такая база данных называется удаленной базой данных.
Технически отличие от сетевого использования файл-серверной архитектуры является то, что при клиент-серверной архитектуре используются промышленные СУБД, такие как MS SQL Server, Oracle, MySQL, Postgress и многие другие.
Приложение же, осуществляющее работу с удаленной базой данных расположено на компьютерах пользователей (хотя у себя на работе в локальной сети я поместил приложение на сеть и как в случае с файл-серверной архитектурой, пользователи запускают его через сеть. У них запускается копия этого приложения). Такое приложение называется клиентским или просто клиентом.
Мы помним, что при файл-серверной архитектуре приложение получает все данные из базы и потом их обрабатывает. При клиент-серверной архитектуре клиентское приложение посылает запрос на выборку серверу. Сервер обрабатывает запрос, извлекает данные из базы данных и отправляет обратно результирующие записи клиентскому приложению.
Что такое сервер? Сервер это специальная программа, которая управляет базой данных. Иначе говоря — это промышленная СУБД (система управления базами данных). То, есть, клиентское приложение отправляет запрос этой самой СУБД.
Таким образом, клиентское приложение получает только нужные пользователю данные, которые удовлетворили запросу, а не все данные таблицы. При этом циркуляция данных в сети резко снижается, подает нагрузка и пропускная способность сети увеличивается.
Заметим, что при этой архитектуре обработкой запроса занимается сервер (СУБД), а при файл-серверной архитектуре — занималось само приложение. Достоинствами клиент-сервера является:
- для доступа к данным вместо навигационного способа используется реляционный (команды языка SQL);
- управлением базой данных занимается не приложение, а сервер, в следствии чего, можно обеспечить надежную защиту данных;
- благодаря тому, что в приложении отсутствует код, который управляет базой данных — их разработка упрощается.
Север — это не только компьютер в сети, но как уже было сказано выше — программа, которая управляет базой данных, то есть СУБД. А так как данные получают с помощью языка SQL, то такую программу (СУБД) называют SQL-сервером, а базу данных называют базой данных SQL.
Для построения архитектуры «Клиент-сервер» приложение должно устанавливать и завершать соединение с базой данных, формировать запросы для SQL-сервера и обрабатывать полученные от него результирующие данные.
Бизнес-правила и удаленные базы данных
Базу данных необходимо все время поддерживать в целостном состоянии. Для этого используются механизмы управления базой данных, называемые бизнес-правилами.
Бизнес-правила можно реализовывать на физическом и программных уровнях.
Если мы говорим об организации бизнес-правил на физическом уровне, то это значит, что все правила организованы при проектировании базы данных и являются частью команд, которые формируют структуру базы данных. Например, при формировании таблицы можно использовать команду, которая определяет какие-нибудь ограничения на ввод данных. Ну то есть, в команде CREATE TABLE, прописываются команды, которые организуют эти правила.
Такие бизнес-правила надежны и их нельзя обойти. Они будут действовать для всех клиентских приложений.
На программном уровне реализация бизнес-правил происходит либо в самом SQL-сервере, либо в клиентском приложении. Но здесь действует такое условие — если бизнес-правила определяются на программном уровне, то они не должны быть определены на физическом.
Если бизнес правила определены на сервере SQL, то в основном для этого используются триггеры. Плюсом подобной организации бизнес-правил является тот факт, что их соблюдение ложится на SQL-сервер. При этом нагрузка на сеть падает. Так же снижается и гибкость приложений в отношении соблюдения этих правил, зато сформированные правила будут соблюдать абсолютно все приложения.
Недостатком такого подходя является плохо развитые (у SQL-серверов) механизмы триггеров и хранимых процедур. Хранимые процедуры — это процедуры (программный код), которые управляют базой данных и хранятся они при этом на сервере, а не в приложении клиента. Но вызываются они из приложения-клиента.
Вообще отличие хранимой процедуры от триггера заключается в том, что хранимая процедура вызывается клиентом, а триггер выполняется автоматически, при совершении какого-то события на сервере. Например, мы удаляем запись из родительской таблицы и при этом событии удаляются также все записи из дочерних таблиц, которые связаны с родительской внешним ключевым полем. Это и есть автоматическое срабатывание триггера. О том, что такое родительские и дочерние таблицы смотрите в посте Виды связей между таблицами .
Если же мы формируем бизнес правила прямо в клиентских приложениях (используя для этого компоненты), то повышается гибкость таких правил, ведь мы можем для отдельно взятого приложения изменить какие-то правила, но одновременно с этим повышается и безопасность управления базой данных, ведь мы можем при этом нарушить целостность базы данных.
Двухуровневые и трехуровневые приложения
Двухуровневые приложения клиент-сервер представляют из себя два уровня. На одном уровне находится СУБД и база данных, на другом клиентское приложение. Схема такого приложения показана на рисунке ниже:
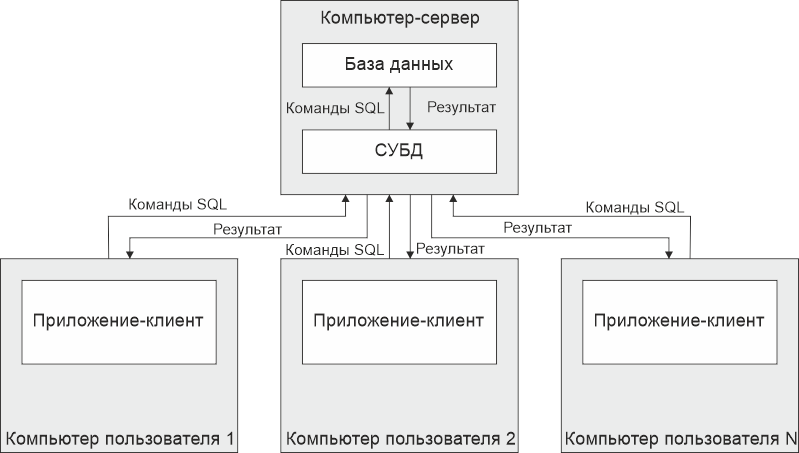
Вообще, к слову говоря, эти два уровня вполне могут находиться и на одном компьютере. То есть, ничто не мешает установить клиентское приложение на тот же компьютер, на котором установлена и СУБД с базой данных. Такая система все-равно будет называться клиент-серверной, поскольку тип системы определяется, прежде всего, выбором промышленной СУБД.
При двухуровневой архитектуре клиентское приложение называется толстым клиентом, поскольку на него возложены такие операции как подключение к серверу, соблюдение бизнес-правил и тому подобное.
Дальнейшее развитие клиент-серверной технологии стало причиной для появления трехуровневой архитектуры клиент-сервер. В такой архитектуре между клиентом и сервером есть промежуточный уровень, который называется сервером приложений.
При трехуровневой (ее еще называют трехзвенная) архитектуре клиентское приложение уже называется тонким клиентом, потому как все общие операции с базой данных, такие как подключение к базе, реализация и поддержка бизнес-правил и другие операции теперь реализованы на этом промежуточном звене, называемом сервером приложений.
Сервер приложений по другому называется брокером данных, то есть посредником данных. И такое посредническое приложение может работать с клиентскими приложениями, написанными под разные операционные системы, будь то Android, Windows, MacOS и других платформ.
Какие же преимущества у трехзвенной архитектуры клиент-сервер? А эти преимущества следующие:
- снижается нагрузка на SQL-сервер;
- несколько упрощается разработка клиентского приложения;
- поведение всех клиентских приложений становится одинаковым благодаря тому, что все они работают по единым правилам;
- настройка этих же клиентских приложений также упрощается;
- появляется независимость от платформы (хотя при двухуровневой архитектуре также можно написать клиента для разных платформ и подключать их к серверу SQL).
Информационные системы, которые разработаны по трехуровневой клиент-серверной технологии называются распределенными.
Принципы построения распределенных приложений
Разработка базы данных и использование сервера при разработке трехуровневых приложений не отличается от двухуровневых. Отличие связано с тем, что при трехуровневой архитектуре создается сервер приложений (брокер данных) и немного по другому проектируется клиентское приложение (тонкий клиент).
Упрощенная схема трехуровневого приложения показана на рисунке ниже:
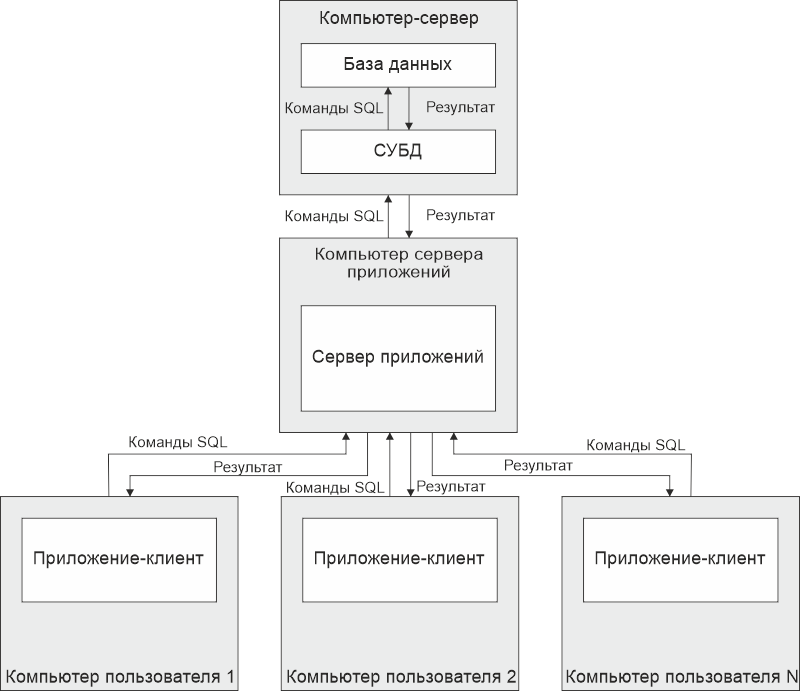
Приложение-клиент и сервер приложений взаимодействуют друг с с другом через интерфейс оператора/интерфейс провайдера или просто провайдера. Это три название одного и того же. Информация через этот интерфейс передается с помощью пакетов данных, которые получаются путем разбиения провайдером всех данных, например результирующего набора, на пакеты.
Затем в зависимости от сетевого протокола происходит кодирование этих данных. Эту операцию также осуществляется провайдер данных.
Когда в приложении-клиенте полученные данные будут отредактированы и сохранены, то провайдер сформирует эти изменения, в так называемые, дельта-пакеты и перешлет их обратно серверу приложений.
В этом дельта-пакете хранится информация до и после изменения, то есть значения, которые были до изменения и уже измененные значения. Затем, перед тем, как окончательно переслать новые данные SQL-серверу, сервер приложений проверяет их на корректность. Определенного рода изменения могут быть не приняты.





